Redis基础数据结构
Redis 基础数据结构
String
SDS 数据结构,采用空间预分配和惰性空间释放来提升效率,缺点就是耗费内存。
struct sdshdr {
int len; //长度
int free; //剩余空间
char buf[]; //字符串数组
}
空间预分配:当一个 SDS 被修改成更长的 buf 时,除了会申请本身需要的内存外,还会额外申请一些空间。
惰性空间:当一个 SDS 被修改成更短的 buf 时,并不会把多余的内存还回去,而是会保存起来。
总结:这种设计的核心思想就是空间换时间,只要free还剩余足够的空间时,下次 String 变长的时候,不会像系统申请内存。
List
链表被广泛用于实现 Redis 的各种功能,比如列表键、发布与订阅、慢查询、监视器等。
struct listNode {
struct listNode * prev; //前置节点
struct listNode * next; //后置节点
void * value;//节点的值
}
Hash
不仅仅是数据类型为 Hash 的才用到 Hash 结构,Redis 本身所有的 K、V 就是一个大 Hash。例如我们经常用的 set key value,key就是 Hash 的键,value就是 Hash 的值。
struct dict {
...
dictht ht[2]; //哈希表
rehashidx == -1 //rehash使用,没有rehash的时候为-1
}
Rehash:每个字典有两个 Hash 表,一个平时使用,一个 Rehash 的时候使用。Rehash 是渐进式的,分别是由以下触发:
- serveCron 定时检测迁移。
- 每次 kv 变更的时候(新增、更新)的时候顺带 Rehash。
Hash 冲突:采用单向链表的方式解决 Hash 冲突,新的冲突元素会被放到链表的表头。
Zset
有序集合可以被用于一些排序场景,底层采用跳跃表实现。
struct zskiplistNode {
struct zskiplistLevel {
struct zskiplistNode *forward;//前进指针
unsigned int span;//跨度
} level[];
struct zskiplistNode *backward;//后退指针
double score;//分值
robj *obj; // 成员对象
};
层高:每个跳跃表节点的层高在 1-32 之间。
跳跃:通过层来实现跨节点跳跃,达到加速访问的效果。
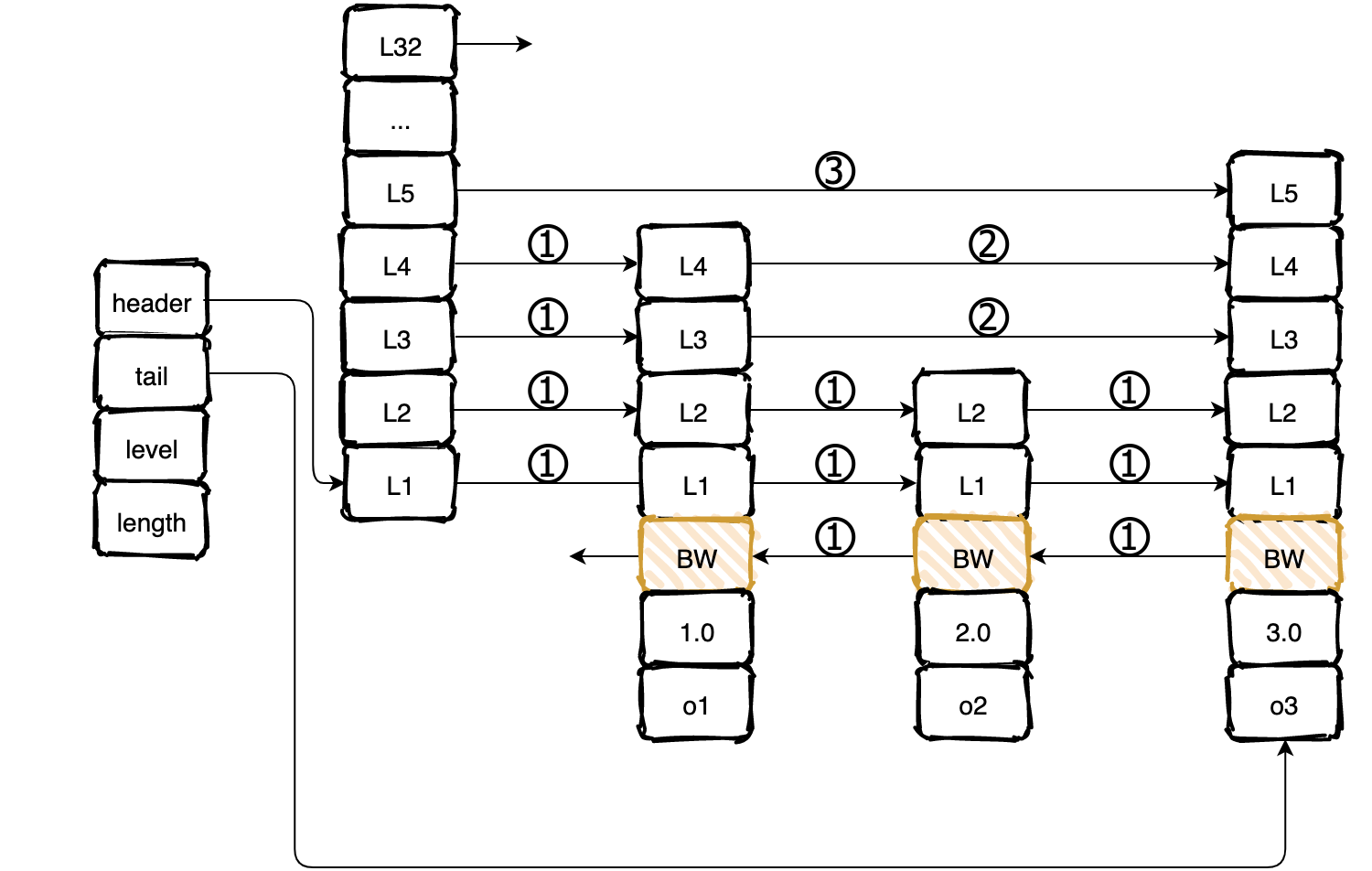
比如 o1 到 o3 只需要通过 L4 层跨度为 2 实现跨节点跳跃。
Set
Set 的底层为了实现内存的节约,会根据集合的类型和数目而采用不同的数据结构来保存,当集合的元素都是整型且数量不多时会采用整数集合来存储。
struct intset {
uint32_t encoding;//编码方式
uint32_t length;//集合包含的元素数量
int8_t contents[];//保存元素的数组
};
整数集合底层实现为数组,在添加元素的时候,根据需要会修改这个数组的类型(比如 int16 升级成 int32)。